

Amazon’s Mechanical Turk (MTurk) is a microtasking marketplace that makes it easier for people to outsource “human intelligence tasks” to an army of workers online.
Common examples of these tasks are labelling data, translating text, transcribing audio, providing descriptions for pictures, etc.
In recent years researchers have made use of this marketplace for conducting studies ranging from psychology and behavioural economics to marketing and product design.
Thousands of papers are now published with this data as well as meta-analyses looking at the nature of the Participant pool.
For many researchers, this can be a high quality and diverse pool of participants that are suitable for many online studies. It can be much faster, more affordable, anonymous, flexible, and scalable than traditional methods.
For these reasons MTurk was the first platform we integrated into Positly to help improve the speed, quality and affordability of online research.
However, there are many difficulties that researchers need to overcome to recruit and manage participants on MTurk. Here we will go through them and how using Positly can solve them.
Why use Positly to conduct MTurk studies?
Automatic quality control
Controlling for quality in research has always been hard, even with participants in a supervised lab setting.
When it comes to online research, the 90s adage applies well: “on the internet, nobody knows you’re a dog” – or a bot as many researchers were recently worried about.
Quality issues range from low attentiveness to downright fraud. At Positly, we’ve worked hard to identify these issues and account for them.
Because we believe in ‘best practice by default’ and building simple, easy interfaces. These settings are on by default, free to researchers, and hidden until you choose to add them as a Participant targeting filter.

Automatic duplicate participant prevention
When conducting studies you often want to prevent the same participant from completing the same, or similar, studies. We use a few different duplicate prevention methods.
Excluding duplicate participant IDs
The most basic way of preventing duplicate participants is based on their unique identifiers. We do this automatically if you select the option to limit to one participant per completion (this is the default setting) when creating a Run.
Excluding duplicate IP and devices
Our digital fingerprinting technology uses browser data, device data, and IP addresses to help ensure that each participant is unique.
Excluding by Previous participation
We often recommend that people conduct Pilot studies and iterative research, however that can make it difficult to prevent people from doing the same study first. We handle this by providing easy exclusion based on Previous participation.

Automatic fraud prevention
Suspicious metadata
We actively monitor and analyse our internal data for any unusual patterns or suspicious behaviour. This includes a range of attributes from browser data and background checks to response patterns in our surveys.
The recent ‘bot’ scare caused some angst in the research community. We worked closely with researchers to identify factors that are indicative of fraudulent participants.
We regularly update our fraud prevention algorithm to detect and prevent this kind of fraudulent data that can be damaging to research.
Note: You can use this handy tool (built by JP Prims, Itay Sisso and Hui Bai) if you have run studies on MTurk in the past and want to see if your data is contaminated. This includes a couple of the same signals that we use in our algorithm.
Geolocation consistency
We use IP address data to detect and restrict to or report on the estimated country of the device used by the participant. IP address estimation is not 100% accurate but this is still a useful data point to monitor for unusual patterns.
Inbuilt quality and attention checks
We use our Demographic pre-survey and Feedback post-survey to conduct checks for quality, consistency, and attention. We regularly update these checks and only select the questions which our studies show to have the highest predictive power for overall participant quality – working very hard to exclude poor quality participants without excluding good quality participants.
These quality and attention checks also help inform our fraud prevention algorithm.
Quality flagging
We encourage researchers to report any data-quality concerns to us. We investigate rigorously, take appropriate action and inform the researchers of the outcomes. These reports also inform our quality algorithms.
Free demographic pre-screening
Researchers frequently use many of the same common screening criteria.
Unfortunately, these can be expensive if you use MTurk’s inbuilt screening. Many screening options are unfeasible because MTurk limits the number of screening criteria to five attributes (two of which are often used for quality).
We pre-screen participants so that researchers can easily target by standard demographics at no extra charge.
Participants also opt-in to automatically have this screening data passed directly into the study or downloaded later by researchers. This saves time for asking common screening questions and removes the expense of pre-screening or the temptation for participants to try and game a screener.
Less manual administration tasks
When using MTurk directly on their interface it can be very burdensome to do some of the most common tasks required to manage a study. We’re constantly working to automate as much of the busywork as possible.
Automatic Approvals
We make it easy to approve participants who have completed your study with our automatic approvals.
Participants are automatically approved if they have completed all the required steps when you place the Completion link at the end of your study,

Rejection management
Researchers are notified in their dashboard when a participant is rejected by our automatic approvals system. They can process these individually or in bulk.
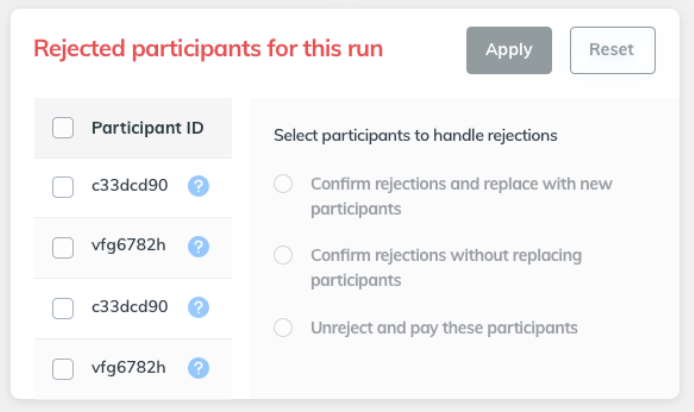
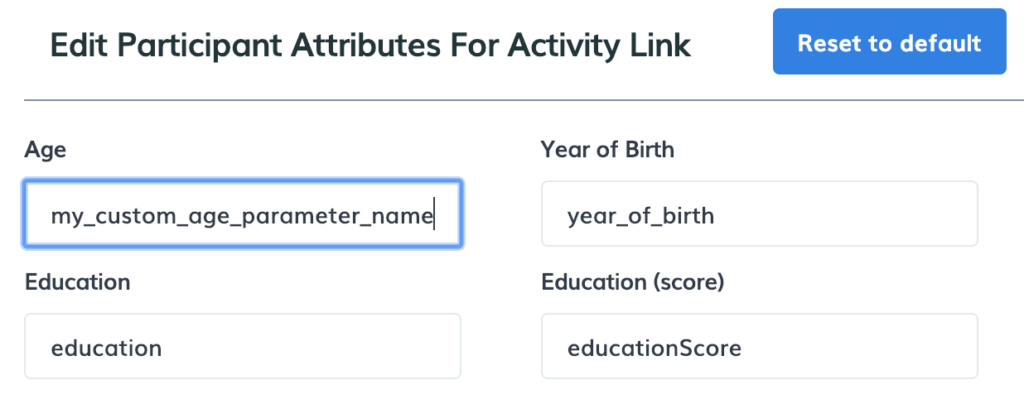
Dynamic Custom attributes
Setting Custom attributes for Participants can make your studies incredibly flexible and powerful. This is particularly helpful in multi-step or longitudinal studies.
While this could be achieved directly on MTurk using Qualifications, they can be difficult to manage and not very dynamic.
Not only do we enable researchers to manually set Custom attributes, but we also enable them to set Custom attributes dynamically using Query string parameters. This way a participant can automatically be enrolled in the right part of the study at the right time and get notified about it.
For example, one of our researchers had a complex screener to identify different psychographic profiles of charity donors. They then wanted to do an immediate follow up with the ‘Cautious Strivers’ type.
In this case they simply gave a different Completion link to each type of donor, for example:
https://app.positly.com/#/f?task_id=ABC123&donor_type=Cautious_Striver
Cost savings
One of our goals is to help make primary human subject research more affordable for researchers. We do this in a number of ways from reducing fees to reducing wasted data and increasing efficiency.
Reducing fees
Masters
Many researchers choose to use “Masters” (participants with a strong record). However, not only are these participants from a smaller pool of less naive participants, but MTurk charges an extra 5% for this option.
Microbatching
Most studies have greater than 10 participants, but unfortunately MTurk increase their fees and charge an extra 20% for this functionality. We keep fees low by breaking up the study into smaller batches.
Demographics
MTurk charges for every demographic you choose to target. Our demographic pre-screening saves between $0.05 and $1.00 per targeting option, per participant ($0.50 for most common attributes).
Reducing wasted data
One of the biggest savings can often be from preventing low-quality wasted data collection. Our suite of quality features helps save researchers both time and money.
Faster completion and increased visibility
Studies can get stalled on MTurk when it is buried in the listing page and participants aren’t notified. We have two features to help improve your study visibility and completion time.
Because we focus on having a simple and clean dashboard we don’t make researchers choose to use (or pay for) features that are almost universally useful. However, if you want to customise these options you can always do so in the advanced settings on the Run confirmation page.
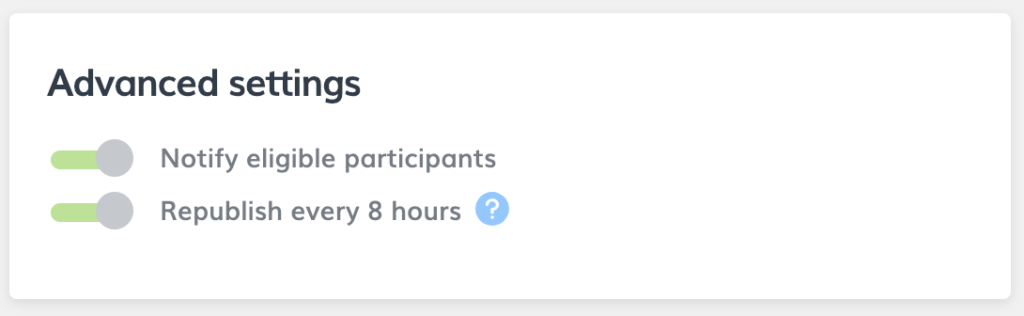
Automatic notifications
Our algorithm automatically notifies the right number of eligible participants that they are able to be part of the study so that studies don’t get stuck and participants don’t miss out.
This is another behind-the-scenes feature which helps studies to complete faster and improves the completion rates of multi-step studies.
Automatic republish
We continue to automatically republish your study until it completes so that it stays visible to participants.
Interface improvements
We have many interface improvements to enable researchers to achieve things they can’t on MTurk, or at least cannot do easily. Such as:
- Editing live studies
- Helpful study statistics
- Helpful participant feedback and management
- Easy management of Custom attributes, Messages and Bonuses
- Performance statistics, interface nudges and reminders (such as the pilot reminder for new Activities) that help researchers improve their studies and get better results
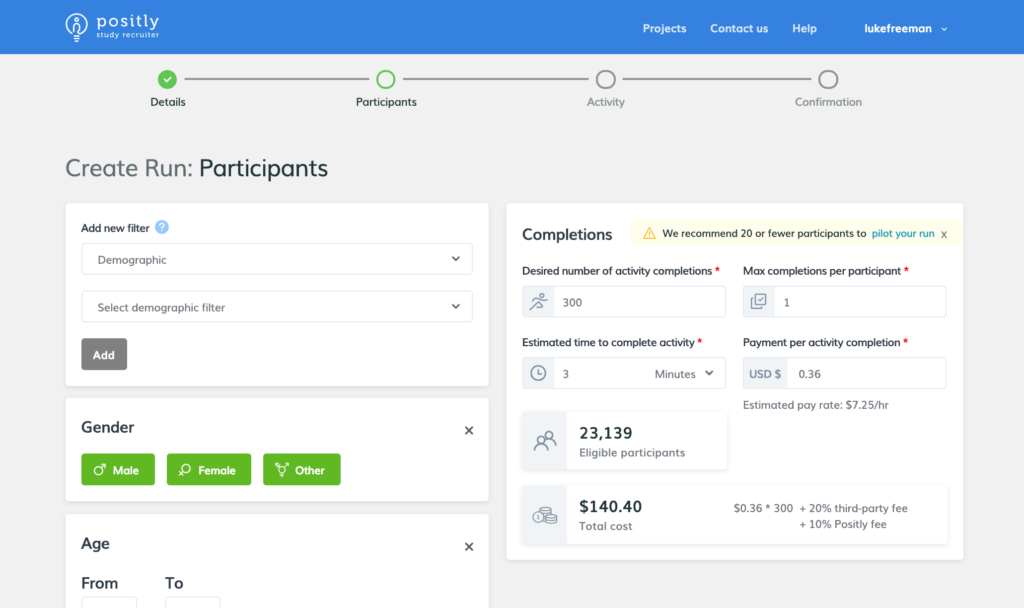
Feedback
Our Feedback post-survey helps researchers to close the loop and ensure that they haven’t made any mistakes in their study design or implementation.
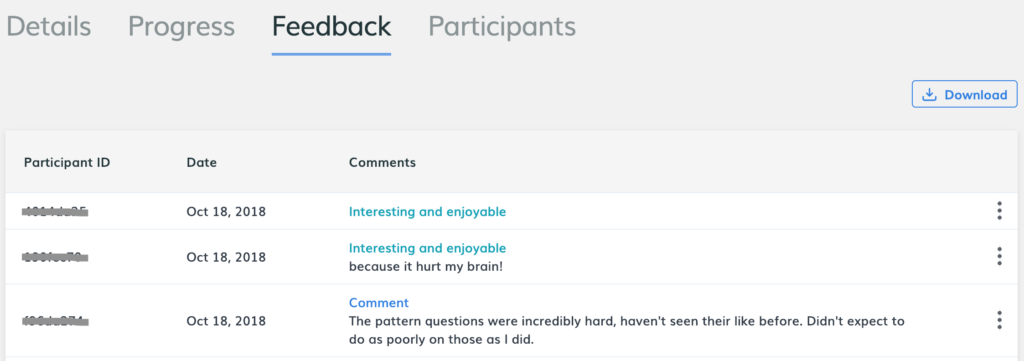
Anonymity
While the MTurk IDs seem to be anonymous and look random, they are not entirely anonymous. We provide an additional layer of participant anonymity by removing the MTurk Worker ID and replacing it with alternate identifiers for researchers using Positly in both the CSV download and the Query string attributes.
How to use Positly to conduct MTurk studies?
While the benefits are big and complex, the actual process is the simple part!

- Create your Project
This is the top level container that holds your runs within a study - Create your Run
- Set up basic run details including pricing
- Select the Participants you want to target
- Add your Activity (link, title and description)
- Set it live and watch the results come in!
First you’ll need to copy the Completion link and put it at the end of your Activity
Once you have created your first Run you can then create more Runs in the same Project and retarget or exclude previous participants.
To learn more details, check out our “How exactly does Positly work?” article or search through our Knowledge Base.
Future development
We have lots more planned to help researchers conducting MTurk studies as well as further platform integrations to help researchers so that they can save time, money and effort on conducting studies across a range of participant pools.
To that end, we’d love to hear from you about what’s most important to you to prioritise.
Leave a comment below or get in touch to let us know what would most improve your life as a researcher. We’re always keen to speak with researchers, so don’t be a stranger!

